
这是第一篇召集群里(230365411)的同学们一起翻译的文章,谢谢大家的义务帮助,本次参与翻译的同学包括王大隆、孙宏亮、吴京润、吴方洲、周敬滨、赵文举。我们也欢迎你的加入!
以下为翻译原文:

为什么使用容器技术?
在我们深入到构建容器的机制之前,首先讨论一下这么做的动机。容器在数据中心拥有的潜能就像游戏机之于游戏。在PC游戏的初期,通常在你开始玩一款游戏之前,都需要安装视频或音频驱动。然而,游戏机提供了不同的体验,与Docker很类似:
- 可预见性:游戏带它自带游戏,随时可运行,不需要下载或更新;
- 迅速:游戏带采用只读存储器,从而获得了如同闪电的速度;
- 简单:游戏带是健壮的,并且很大程度上拥有儿童防护措施,它们是真正的即插即用;
- 可预见性、迅速、简单,在扩展规模方面都是好东西。 Docker容器提供了构建模块,使我们的数据中心更容易运行、更适合使应用成为独立模块,随时就绪的单元就像是游戏机上的游戏带。
引导程序
为了努力实现容器化,你需要同时具备开发和运维技能。首先,与你的运维团队交流,你需要确信你的容器能够完全复制于你的生产环境。如果你运行在OSX(或 windows)桌面操作系统,但部署在Linux上,使用一个虚拟机(比如Vagrant)作为本地测试环境。第一步,更新你的操作系统和安装支持包。 挑选一个基础镜像匹配你的生产环境(我们使用Ubuntu14.01),不能出差错——你不会想处理容器化和操作系统/包在同一时间升级所带来的麻烦。
选择容器类型
在容器类型方面Docker为你提供了足够的选择空间,从一个单进程的“瘦”容器到一个让你觉得类似于传统虚拟机的“胖”容器(例如,Phusion)。
我们选择去遵循“廋”容器方式,从容器内部去除一些无关的组件。虽然从两种方式作出选择是困难的,但是我们更青睐于小的那种,因为容器简单化会消耗更少的CPU和内存。这种方式被详细的说明在 Docker blog中。
环境配置
在生产环境中,我们使用Chef这一部署工具来管理系统的各个节点。这样的话,我们可以轻松做到在一个容器之中运行Chef,然而我们并不希 望某些服务在每一个容器中都运行,比如:日志的索引服务,运行状态采集服务等。而Chef的使用无疑使得很多服务都会重复安装在不必要的容器中,由于无法 忍受以上徒劳的重复工作,我们选择在每一台运行Docker的宿主机上共享同一份这些服务的副本。
如何将容器做得轻量级,关键是:将Chef部署工具的运行脚本转换为一个Dockerfile(这部分内容,我们后来将其替换为一个自 定义的Docker build流程,之后的文章会涉及)。Docker的诞生,可以说是天赐良机,使运维人员评估内部的生产环境,并回顾以及整理整个系 统生命周期中到底需要什么。在这一环节中,对于系统的的割舍请尽量无情,同时也要保证在code review过程中尽量做到谨慎。
其实,整个过程,并没有听起来那么艰难。最终,我们团队以一个125行Dockerfile的形式告终,而该Dockerfile则是 定义了在Shopify上所有容器需要共享的基础镜像。该基础镜像包含了25 个包,这些包中包括跨度较大的编程语言运行时(Ruby、Python和 Node),还有多种开发工具(Git、Vim、build-essential和Go),也有一些需要共享使用的库文件。同时,基础镜像中还包含了一系 列工具脚本用以任务的运行,比如通过调整参数来启动Ruby,或者向Datadog发送监控数据等。
在以上环境下,我们的应用可以很随意在这个基础镜像上添加自身的特定需求。尽管如此,我们最大的应用也仅仅是添加了一些操作系统的依赖包,所以总体来讲,我们的基础镜像还是相对简洁精干的。
容器的100定律
在选择将何种服务容器化时,可以首先假设你有100个小容器运行在同一个host上,然后想一下是否真的有必要运行100个服务的副本,还是大家共享一个单独的host更好。
以下是一些实例说明我们如何根据100定律来决定如何使用容器的:
日志索引:日志对于诊断错误至关重要,尤其在容器退出,文件系统消失后显得更为重要。我们特意避免了修改应用程序的日志行为(比如强 制它们重新定向到系统日志),并且允许它们继续写日志到文件系统。运行100个日志代理似乎是错误的做法,所以我们创建一个后台程序去处理以下重要任务:
- 运行在host端,并订阅Docker event;
- 在容器启动时,配置日志索引来监视容器;
- 容器销毁时,删除索引指令。
- 为了确保容器退出时,所有的日志都被编入索引,你可能需要稍微延迟容器的销毁。
统计:Shopify在几个级别(系统,中间件和应用程序)上都生成了运行时统计,得到的结果通过代理或应用程序代码转述。
- 许多我们的统计结果可以通过StasD传输,幸运的是我们可以配置Datadog的host端去接收容器传来的流量,通过适当的配置,就可以将StasD接收的地址传给容器;
- 由于容器从本质上来说就是进程树,所以一个host端的系统监控代理可以看到容器边界共享一个单一的系统监控也是自由的;
- 从一个更加以容器为中心的角度出发,来考虑Docker和Datadog的集成,会添加Docker metrics到host端的监控代理;
- 应用级别的metrics大多数运行得还可以,它们或者通过StasD发送事件,或者直接和其它服务对话。为一个容器指定名字很重要,这样一来metrics也更容易读。
Kafka:我们使用Kafka来实时处理从Shopify堆栈到合作伙伴的事件。我们使用Ruby on Rail代码来发布Kafka事件,生成信息,然后放到SysV消息队列。一个Go语言写的后台程序会在队列中取出消息发送给Kafka。这减少了 Ruby进程的时间,我们也能更好地应对Kafka服务器的事故。有一点不好的是,SysV消息队列是IPC namespace的一部分,所以我们不能用来连接container:host。我们的解决方案是在host上添加一个socket端,用来将消息放到 SysV队列。
100定律的使用需要一定的灵活性。一些情况下,仅仅需要写一下组件的“黏合器”,也可以通过配置来达到目的。最终,你应该获得一个容器,内含你的应用程序运行所需的东西,以及一个提供了Docker托管和共享服务的主机环境。
将你的应用容器化
随着环境的就绪,我们可以把注意力转到程序的容器化上来。
我们更倾向于thin container能准确地做一件事。例如一个unicorn(Unicorn是一个Unix和局域网/本地主机优化的HTTP服务器)master和工 作线程服务web请求,或者一个Resque(Resque使用Redis创建后台任务,存储进队列,并随后执行。它是Rails下最常用的后台任务管理 工具之一)工作线程服务一个特定的队列。thin container允许细粒度的缩放比例(一般是指远程方法调用的接口的颗粒大小),以满足需求。例如,我们可以增加检查垃圾邮件攻击响应的 Resque工作线程的数目。
我们发现采取一些标准约定对于在容器中的代码布局会有用处:
- 应用程序总是root在容器内部的/app下;
- 应用程序通常通过单个端口发布服务;
我们还确立了一些容器化git repo(repo封装了对git的操作)的约定:
- /container/files 拥有一个在其建立时就被直接复制进容器的文件树,举个例子,请求 Splunk 索引的应用程序日志,它添加/container/files/etc/splunk.d/inputs.conf 文件进你的git repo就足够了(控制日志索引的责任转移到开发者,这是一个微妙而重大的转变,过去这都是运维管理员的工作);
-
/container/compile是一个 shell 脚本,编译您的应用程序,并生成一个随时可运行的容器。建立此文件并适应您的应用程序,是最复杂的地方;
-
/container /roles.json保存命令行以机器可读的形式用来运行该工作负载。很多我们的应用程序以多个角色,运行相同代码库,一些处理 web 流量同时处理后台任务。这部分的灵感来自 Heroku 的 procfile。以下是一个示例的roles.json文件:
我们用一个简单的Makefile驱动建立,也可以本地运行。我们的 Dockerfile 看起来像这样:取消编译阶段的目标是产生一个是即刻准备运行的容器。Docker关键的优势之一就是在容器启动时超级快速启动而不被损坏因为额外的工作。为了实现这一目标您需要了解您的整个部署过程。 举几个例子:
- 我们正在使用Capistrano(Capistrano是一种在多台服务器上运行脚本的开源工具,它主要用于部署web应用)将代码部署到机器,并且asset编译以前发生的事情作为部署的一部分。通过移动资产编译到容器里生成,部署新代码由更简单、快几分钟。
- 我们的unicorn 主机启动来从table 模型中获取数据(Table 对象代表一个 HTML 表格。)不只这是缓慢的,而且我们更小的容器大小意味着将需要更多的数据库连接。另一方面,它是可能做到这一点(获取数据)的在容器建立的时候,以加速启动。
在本例中,编译阶段包括以下的逻辑步骤:
- bundle install
- asset compile
- database setup
为了保持这一公告(邮件)的大小合理,我们简化了一些细节。密钥管理是一个主要的细节,我们还没有在这里讨论。不要将其登记入源码管理。我们已经获取了用来加密密钥的代码,致力于该主题的博客帖子很快就会来了。
调试和细节
运行在容器中的应用程序和容器之外的表现绝大多数情况是相同的。此外,你的大多数调试工具(例如:strace,gdb,/proc/filesystem)是运行在Docker所在的host上。还有大家熟悉的工具nsenter或nsinit,可以用他们挂载到一个运行中的容器里进行调试。
docker exec,作为docker 1.3.0版本中提供的新工具,能够被用来向运行的容器中注入进程。但是,不幸的是,如果你注入进程需要root权限,你还是需要通过nsenter,有些地方的情况可能不会像人们预料的那样。
进程分层
尽管我们运行轻量级的容器,仍然需要初始化进程(pid=1)从而与监控工具,后台管理,服务发现等做到紧密集成,也能给我们细粒度的健康监测。
除了初始化进程,我们在每个容器中添加了一个ppidshim进程(pid=2),应用程序进程的pid=3。由于ppdishim进程的存在,应用程序没有直接继承自初始化进程,避免它们以为自己是后台守护进程,造成错误的后果。
最终的进程层次是这样的:
Signals
如果你在使用容器技术,你很可能会修改现有的运行脚本或写一套新的脚本,其中包含了docker run的调用。默认的情况下,docker run会代理signal到你的应用程序,所以你必须理解应用程序是如何解读signal的。
标准的UNIX做法是发送SIGTERM去请求有序地关闭一个进程。为了确保应用程序遵守这个惯例,Resque使用SIGQUIT来有序地关闭进程,SIGTERM来紧急关闭进程。幸运的是,Resque可以被配置使用SIGTERM来优雅地关闭进程。
Hostnames
我们选择容器名称来描述工作负载(例如 unicorn-1, resque-2),并结合这些主机名来进行简单追溯。最终的结果会是这 样:unicorn-1.server2.shopify.com.我们使用Docker的主机名标签将结果传入容器中,这使大多数应用程序报告出正确的 值。一些程序(Ruby)询问主机名来得到缩略名(unicorn-1),而不用询问预期的FQDN。由于Docker管理着/etc /resolv.conf 文件,我们当前版本不允许任意变更,所以我们通过LD_PRELOAD,重写了gethostname()和uname()的 方法,并注入到library中。最终结果会是,监控工具发布我们想要得到的主机名却不用去更改应用程序代码。
注册和部署
我们发现构建容器的过程中复制‘bare metal’的行为相当于一个不断调试的过程。如果你是理智的的,你肯定想自动化的去构建容器。
为了每个人都能push,我们使用github commit hook去触发一个容器的构建,构建过程中我们会提交状态日志来判定是否构建成功。我们使用git提交SHA到容器的“docker tag”,所以你能准确的看到什么样的代码版本被包含在容器中。为了更容易被脚本调试和使用,我们同样也把SHA放到容器里的一个文件中(/app/REVISION)。
一旦你的构建是正常的,你会想把容器push到一个中央的注册表仓库。为了提高部署速度和减少外部依赖我们选择运行数据中心中自己的库。 我们在Nginx反向代理(其中缓存了GET请求的内容)背后运行多个标准Python注册表的副本,如下图所示:
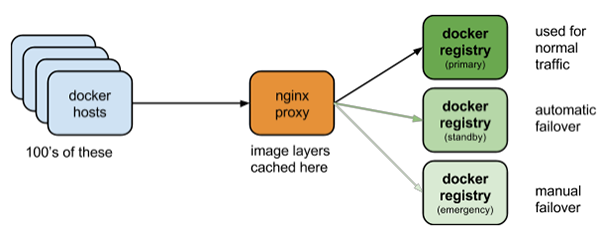
当多个Docker主机请求相同的镜像时,我们发现大型网络接口(10 Gbps)和反向代理,在解决”thundering herd“这样的代码部署相关的问题是很有效的。代理方法还允许我们运行多种类型的库,并在发生故障的情况下,提供自动故障转移。
如果遵循这个蓝图,你可以自动化去构建容器,并且安全地把容器存储在一个中央仓库注册表中,这些都可以融入你的部署过程。
在本系列的下一篇文章,作者将描述如何管理应用程序的秘密。